- Machine Learning Basics
- Machine Learning - Home
- Machine Learning - Getting Started
- Machine Learning - Basic Concepts
- Machine Learning - Python Libraries
- Machine Learning - Applications
- Machine Learning - Life Cycle
- Machine Learning - Required Skills
- Machine Learning - Implementation
- Machine Learning - Challenges & Common Issues
- Machine Learning - Limitations
- Machine Learning - Reallife Examples
- Machine Learning - Data Structure
- Machine Learning - Mathematics
- Machine Learning - Artificial Intelligence
- Machine Learning - Neural Networks
- Machine Learning - Deep Learning
- Machine Learning - Getting Datasets
- Machine Learning - Categorical Data
- Machine Learning - Data Loading
- Machine Learning - Data Understanding
- Machine Learning - Data Preparation
- Machine Learning - Models
- Machine Learning - Supervised
- Machine Learning - Unsupervised
- Machine Learning - Semi-supervised
- Machine Learning - Reinforcement
- Machine Learning - Supervised vs. Unsupervised
- Machine Learning Data Visualization
- Machine Learning - Data Visualization
- Machine Learning - Histograms
- Machine Learning - Density Plots
- Machine Learning - Box and Whisker Plots
- Machine Learning - Correlation Matrix Plots
- Machine Learning - Scatter Matrix Plots
- Statistics for Machine Learning
- Machine Learning - Statistics
- Machine Learning - Mean, Median, Mode
- Machine Learning - Standard Deviation
- Machine Learning - Percentiles
- Machine Learning - Data Distribution
- Machine Learning - Skewness and Kurtosis
- Machine Learning - Bias and Variance
- Machine Learning - Hypothesis
- Regression Analysis In ML
- Machine Learning - Regression Analysis
- Machine Learning - Linear Regression
- Machine Learning - Simple Linear Regression
- Machine Learning - Multiple Linear Regression
- Machine Learning - Polynomial Regression
- Classification Algorithms In ML
- Machine Learning - Classification Algorithms
- Machine Learning - Logistic Regression
- Machine Learning - K-Nearest Neighbors (KNN)
- Machine Learning - Naïve Bayes Algorithm
- Machine Learning - Decision Tree Algorithm
- Machine Learning - Support Vector Machine
- Machine Learning - Random Forest
- Machine Learning - Confusion Matrix
- Machine Learning - Stochastic Gradient Descent
- Clustering Algorithms In ML
- Machine Learning - Clustering Algorithms
- Machine Learning - Centroid-Based Clustering
- Machine Learning - K-Means Clustering
- Machine Learning - K-Medoids Clustering
- Machine Learning - Mean-Shift Clustering
- Machine Learning - Hierarchical Clustering
- Machine Learning - Density-Based Clustering
- Machine Learning - DBSCAN Clustering
- Machine Learning - OPTICS Clustering
- Machine Learning - HDBSCAN Clustering
- Machine Learning - BIRCH Clustering
- Machine Learning - Affinity Propagation
- Machine Learning - Distribution-Based Clustering
- Machine Learning - Agglomerative Clustering
- Dimensionality Reduction In ML
- Machine Learning - Dimensionality Reduction
- Machine Learning - Feature Selection
- Machine Learning - Feature Extraction
- Machine Learning - Backward Elimination
- Machine Learning - Forward Feature Construction
- Machine Learning - High Correlation Filter
- Machine Learning - Low Variance Filter
- Machine Learning - Missing Values Ratio
- Machine Learning - Principal Component Analysis
- Machine Learning Miscellaneous
- Machine Learning - Performance Metrics
- Machine Learning - Automatic Workflows
- Machine Learning - Boost Model Performance
- Machine Learning - Gradient Boosting
- Machine Learning - Bootstrap Aggregation (Bagging)
- Machine Learning - Cross Validation
- Machine Learning - AUC-ROC Curve
- Machine Learning - Grid Search
- Machine Learning - Data Scaling
- Machine Learning - Train and Test
- Machine Learning - Association Rules
- Machine Learning - Apriori Algorithm
- Machine Learning - Gaussian Discriminant Analysis
- Machine Learning - Cost Function
- Machine Learning - Bayes Theorem
- Machine Learning - Precision and Recall
- Machine Learning - Adversarial
- Machine Learning - Stacking
- Machine Learning - Epoch
- Machine Learning - Perceptron
- Machine Learning - Regularization
- Machine Learning - Overfitting
- Machine Learning - P-value
- Machine Learning - Entropy
- Machine Learning - MLOps
- Machine Learning - Data Leakage
- Machine Learning - Resources
- Machine Learning - Quick Guide
- Machine Learning - Useful Resources
- Machine Learning - Discussion
Machine Learning - Histograms
A histogram is a bar graph-like representation of the distribution of a variable. It shows the frequency of occurrences of each value of the variable. The x-axis represents the range of values of the variable, and the y-axis represents the frequency or count of each value. The height of each bar represents the number of data points that fall within that value range.
Histograms are useful for identifying patterns in data, such as skewness, modality, and outliers. Skewness refers to the degree of asymmetry in the distribution of the variable. Modality refers to the number of peaks in the distribution. Outliers are data points that fall outside of the range of typical values for the variable.
Python Implementation of Histograms
Python provides several libraries for data visualization, such as Matplotlib, Seaborn, Plotly, and Bokeh. For the example given below, we will use Matplotlib to implement histograms.
We will use the breast cancer dataset from the Sklearn library for this example. The breast cancer dataset contains information about the characteristics of breast cancer cells and whether they are malignant or benign. The dataset has 30 features and 569 samples.
Example
Let's start by importing the necessary libraries and loading the dataset −
import matplotlib.pyplot as plt from sklearn.datasets import load_breast_cancer data = load_breast_cancer()
Next, we will create a histogram of the mean radius feature of the dataset −
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[:,0], bins=20)
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.show()
In this code, we have used the hist() function from Matplotlib to create a histogram of the mean radius feature of the dataset. We have set the number of bins to 20 to divide the data range into 20 intervals. We have also added labels to the x and y axes using the xlabel() and ylabel() functions.
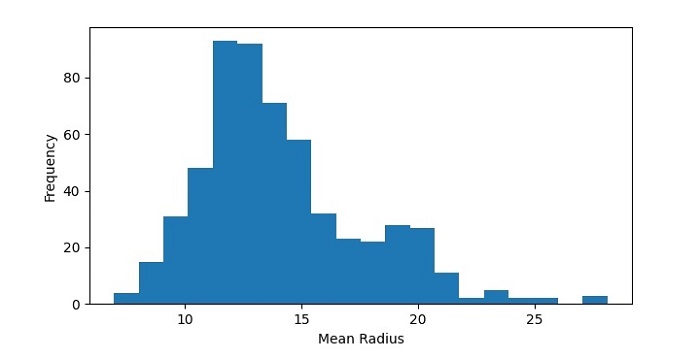
Output
The resulting histogram shows the distribution of mean radius values in the dataset. We can see that the data is roughly normally distributed, with a peak around 12-14.
Histogram with Multiple Data Sets
We can also create a histogram with multiple data sets to compare their distributions. Let's create histograms of the mean radius feature for both the malignant and benign samples −
Example
plt.figure(figsize=(7.2, 3.5))
plt.hist(data.data[data.target==0,0], bins=20, alpha=0.5, label='Malignant')
plt.hist(data.data[data.target==1,0], bins=20, alpha=0.5, label='Benign')
plt.xlabel('Mean Radius')
plt.ylabel('Frequency')
plt.legend()
plt.show()
In this code, we have used the hist() function twice to create two histograms of the mean radius feature, one for the malignant samples and one for the benign samples. We have set the transparency of the bars to 0.5 using the alpha parameter so that they don't overlap completely. We have also added a legend to the plot using the legend() function.
Output
On executing this code, you will get the following plot as the output −
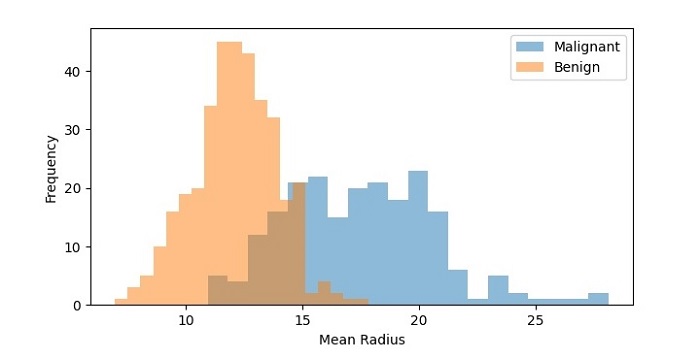
The resulting histogram shows the distribution of mean radius values for both the malignant and benign samples. We can see that the distributions are different, with the malignant samples having a higher frequency of higher mean radius values.