- Machine Learning Basics
- Machine Learning - Home
- Machine Learning - Getting Started
- Machine Learning - Basic Concepts
- Machine Learning - Python Libraries
- Machine Learning - Applications
- Machine Learning - Life Cycle
- Machine Learning - Required Skills
- Machine Learning - Implementation
- Machine Learning - Challenges & Common Issues
- Machine Learning - Limitations
- Machine Learning - Reallife Examples
- Machine Learning - Data Structure
- Machine Learning - Mathematics
- Machine Learning - Artificial Intelligence
- Machine Learning - Neural Networks
- Machine Learning - Deep Learning
- Machine Learning - Getting Datasets
- Machine Learning - Categorical Data
- Machine Learning - Data Loading
- Machine Learning - Data Understanding
- Machine Learning - Data Preparation
- Machine Learning - Models
- Machine Learning - Supervised
- Machine Learning - Unsupervised
- Machine Learning - Semi-supervised
- Machine Learning - Reinforcement
- Machine Learning - Supervised vs. Unsupervised
- Machine Learning Data Visualization
- Machine Learning - Data Visualization
- Machine Learning - Histograms
- Machine Learning - Density Plots
- Machine Learning - Box and Whisker Plots
- Machine Learning - Correlation Matrix Plots
- Machine Learning - Scatter Matrix Plots
- Statistics for Machine Learning
- Machine Learning - Statistics
- Machine Learning - Mean, Median, Mode
- Machine Learning - Standard Deviation
- Machine Learning - Percentiles
- Machine Learning - Data Distribution
- Machine Learning - Skewness and Kurtosis
- Machine Learning - Bias and Variance
- Machine Learning - Hypothesis
- Regression Analysis In ML
- Machine Learning - Regression Analysis
- Machine Learning - Linear Regression
- Machine Learning - Simple Linear Regression
- Machine Learning - Multiple Linear Regression
- Machine Learning - Polynomial Regression
- Classification Algorithms In ML
- Machine Learning - Classification Algorithms
- Machine Learning - Logistic Regression
- Machine Learning - K-Nearest Neighbors (KNN)
- Machine Learning - Naïve Bayes Algorithm
- Machine Learning - Decision Tree Algorithm
- Machine Learning - Support Vector Machine
- Machine Learning - Random Forest
- Machine Learning - Confusion Matrix
- Machine Learning - Stochastic Gradient Descent
- Clustering Algorithms In ML
- Machine Learning - Clustering Algorithms
- Machine Learning - Centroid-Based Clustering
- Machine Learning - K-Means Clustering
- Machine Learning - K-Medoids Clustering
- Machine Learning - Mean-Shift Clustering
- Machine Learning - Hierarchical Clustering
- Machine Learning - Density-Based Clustering
- Machine Learning - DBSCAN Clustering
- Machine Learning - OPTICS Clustering
- Machine Learning - HDBSCAN Clustering
- Machine Learning - BIRCH Clustering
- Machine Learning - Affinity Propagation
- Machine Learning - Distribution-Based Clustering
- Machine Learning - Agglomerative Clustering
- Dimensionality Reduction In ML
- Machine Learning - Dimensionality Reduction
- Machine Learning - Feature Selection
- Machine Learning - Feature Extraction
- Machine Learning - Backward Elimination
- Machine Learning - Forward Feature Construction
- Machine Learning - High Correlation Filter
- Machine Learning - Low Variance Filter
- Machine Learning - Missing Values Ratio
- Machine Learning - Principal Component Analysis
- Machine Learning Miscellaneous
- Machine Learning - Performance Metrics
- Machine Learning - Automatic Workflows
- Machine Learning - Boost Model Performance
- Machine Learning - Gradient Boosting
- Machine Learning - Bootstrap Aggregation (Bagging)
- Machine Learning - Cross Validation
- Machine Learning - AUC-ROC Curve
- Machine Learning - Grid Search
- Machine Learning - Data Scaling
- Machine Learning - Train and Test
- Machine Learning - Association Rules
- Machine Learning - Apriori Algorithm
- Machine Learning - Gaussian Discriminant Analysis
- Machine Learning - Cost Function
- Machine Learning - Bayes Theorem
- Machine Learning - Precision and Recall
- Machine Learning - Adversarial
- Machine Learning - Stacking
- Machine Learning - Epoch
- Machine Learning - Perceptron
- Machine Learning - Regularization
- Machine Learning - Overfitting
- Machine Learning - P-value
- Machine Learning - Entropy
- Machine Learning - MLOps
- Machine Learning - Data Leakage
- Machine Learning - Resources
- Machine Learning - Quick Guide
- Machine Learning - Useful Resources
- Machine Learning - Discussion
Machine Learning - Decision Trees Algorithm
The Decision Tree algorithm is a hierarchical tree-based algorithm that is used to classify or predict outcomes based on a set of rules. It works by splitting the data into subsets based on the values of the input features. The algorithm recursively splits the data until it reaches a point where the data in each subset belongs to the same class or has the same value for the target variable. The resulting tree is a set of decision rules that can be used to make predictions or classify new data.
The Decision Tree algorithm works by selecting the best feature to split the data at each node. The best feature is the one that provides the most information gain or the most reduction in entropy. Information gain is a measure of the amount of information gained by splitting the data at a particular feature, while entropy is a measure of the randomness or disorder in the data. The algorithm uses these measures to determine the best feature to split the data at each node.
The example of a binary tree for predicting whether a person is fit or unfit providing various information like age, eating habits and exercise habits, is given below −
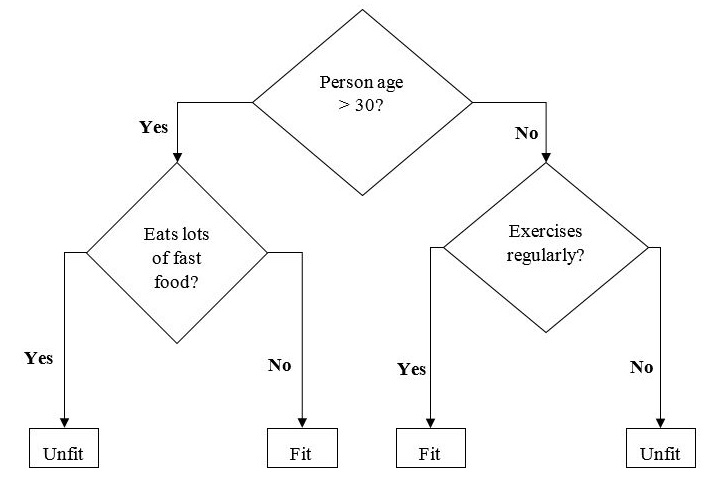
In the above decision tree, the question are decision nodes and final outcomes are leaves.
Types of Decision Tree Algorithm
There are two main types of Decision Tree algorithm −
Classification Tree − A classification tree is used to classify data into different classes or categories. It works by splitting the data into subsets based on the values of the input features and assigning each subset to a different class.
Regression Tree − A regression tree is used to predict numerical values or continuous variables. It works by splitting the data into subsets based on the values of the input features and assigning each subset a numerical value.
Implementation in Python
Let's implement the Decision Tree algorithm in Python using a popular dataset for classification tasks named Iris dataset. It contains 150 samples of iris flowers, each with four features: sepal length, sepal width, petal length, and petal width. The flowers belong to three classes: setosa, versicolor, and virginica.
First, we will import the necessary libraries and load the dataset −
import numpy as np from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier # Load the iris dataset iris = load_iris() # Split the dataset into training and testing sets X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
We then create an instance of the Decision Tree classifier and train it on the training set −
# Create a Decision Tree classifier dtc = DecisionTreeClassifier() # Fit the classifier to the training data dtc.fit(X_train, y_train)
We can now use the trained classifier to make predictions on the testing set −
# Make predictions on the testing data y_pred = dtc.predict(X_test)
We can evaluate the performance of the classifier by calculating its accuracy −
# Calculate the accuracy of the classifier
accuracy = np.sum(y_pred == y_test) / len(y_test)
print("Accuracy:", accuracy)
We can visualize the Decision Tree using Matplotlib library −
import matplotlib.pyplot as plt from sklearn.tree import plot_tree # Visualize the Decision Tree using Matplotlib plt.figure(figsize=(20,10)) plot_tree(dtc, filled=True, feature_names=iris.feature_names, class_names=iris.target_names) plt.show()
The plot_tree function from the sklearn.tree module can be used to plot the Decision Tree. We can pass in the trained Decision Tree classifier, the filled argument to fill the nodes with color, the feature_names argument to label the features, and the class_names argument to label the target classes. We also specify the figsize argument to set the size of the figure and call the show function to display the plot.
Complete Implementation Example
Given below is the complete implementation example of Decision Tree Classification algorithm in python using the iris dataset −
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# Load the iris dataset
iris = load_iris()
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.3, random_state=0)
# Create a Decision Tree classifier
dtc = DecisionTreeClassifier()
# Fit the classifier to the training data
dtc.fit(X_train, y_train)
# Make predictions on the testing data
y_pred = dtc.predict(X_test)
# Calculate the accuracy of the classifier
accuracy = np.sum(y_pred == y_test) / len(y_test)
print("Accuracy:", accuracy)
# Visualize the Decision Tree using Matplotlib
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(20,10))
plot_tree(dtc, filled=True, feature_names=iris.feature_names,
class_names=iris.target_names)
plt.show()
Output
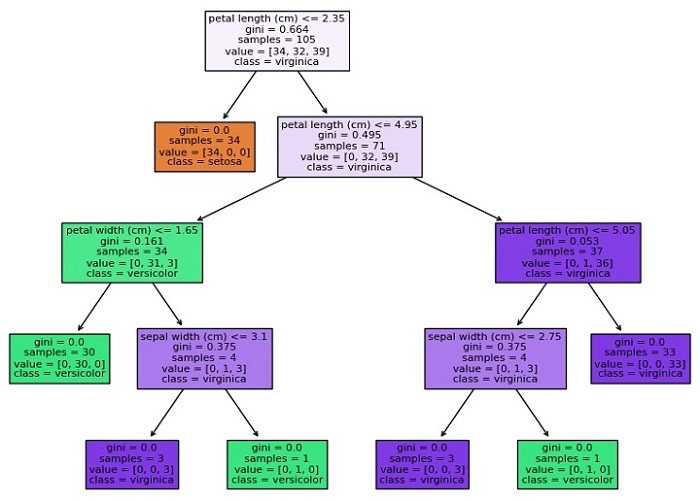
This will create a plot of the Decision Tree that looks like this −
Accuracy: 0.9777777777777777
As you can see, the plot shows the structure of the Decision Tree, with each node representing a decision based on the value of a feature, and each leaf node representing a class or numerical value. The color of each node indicates the majority class or value of the samples in that node, and the numbers at the bottom indicate the number of samples that reach that node.