- Big Data Analytics Tutorial
- Big Data Analytics - Home
- Big Data Analytics - Overview
- Big Data Analytics - Characteristics
- Big Data Analytics - Data Life Cycle
- Big Data Analytics - Architecture
- Big Data Analytics - Methodology
- Big Data Analytics - Core Deliverables
- Big Data Adoption & Planning Considerations
- Big Data Analytics - Key Stakeholders
- Big Data Analytics - Data Analyst
- Big Data Analytics - Data Scientist
- Big Data Analytics Project
- Data Analytics - Problem Definition
- Big Data Analytics - Data Collection
- Big Data Analytics - Cleansing data
- Big Data Analytics - Summarizing
- Big Data Analytics - Data Exploration
- Big Data Analytics - Data Visualization
- Big Data Analytics Methods
- Big Data Analytics - Introduction to R
- Data Analytics - Introduction to SQL
- Big Data Analytics - Charts & Graphs
- Big Data Analytics - Data Tools
- Data Analytics - Statistical Methods
- Advanced Methods
- Machine Learning for Data Analysis
- Naive Bayes Classifier
- K-Means Clustering
- Association Rules
- Big Data Analytics - Decision Trees
- Logistic Regression
- Big Data Analytics - Time Series
- Big Data Analytics - Text Analytics
- Big Data Analytics - Online Learning
- Big Data Analytics Useful Resources
- Big Data Analytics - Quick Guide
- Big Data Analytics - Resources
- Big Data Analytics - Discussion
Big Data Analytics - Architecture
What is Big Data Architecture?
Big data architecture is specifically designed to manage data ingestion, data processing, and analysis of data that is too large or complex. A big size data cannot be store, process and manage by conventional relational databases. The solution is to organize technology into a structure of big data architecture. Big data architecture is able to manage and process data.
Key Aspects of Big Data Architecture
The following are some key aspects of big data architecture −
- To store and process large size data like 100 GB in size.
- To aggregates and transform of a wide variety of unstructured data for analysis and reporting.
- Access, processing and analysis of streamed data in real time.
Diagram of Big Data Architecture
The following figure shows Big Data Architecture with its sequential arrangements of different components. The outcomes of one component work as an input to another component and this process flow continues till to outcome of processed data.Here is the diagram of big data architecture −
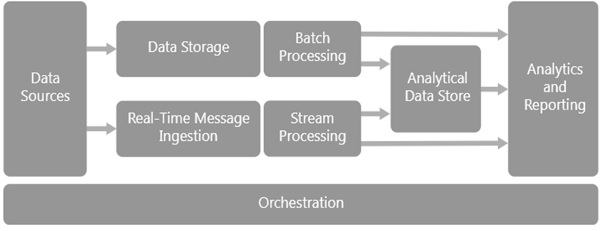
Components of Big Data Architecture
The following are the different components of big data architecture −
Data Sources
All big data solutions start with one or more data sources. The Big Data Architecture accommodates various data sources and efficiently manages a wide range of data types. Some common data sources in big data architecture include transactional databases, logs, machine-generated data, social media and web data, streaming data, external data sources, cloud-based data, NOSQL databases, data warehouses, file systems, APIs, and web services.
These are only a few instances; in reality, the data environment is broad and constantly changing, with new sources and technologies developing over time. The primary challenge in big data architecture is successfully integrating, processing, and analyzing data from various sources in order to gain relevant insights and drive decision-making.
Data Storage
Data storage is the system for storing and managing large amounts of data in big data architecture. Big data includes handling large amounts of structured, semi-structured, and unstructured data; traditional relational databases often prove inadequate due to scalability and performance limitations.
Distributed file stores, capable of storing large volumes of files in various formats, typically store data for batch processing operations. People often refer to this type of store as a data lake. You can use Azure Data Lake Storage or blob containers in Azure Storage for this purpose. In a big data architecture, the following image shows the key approaches to data storage −
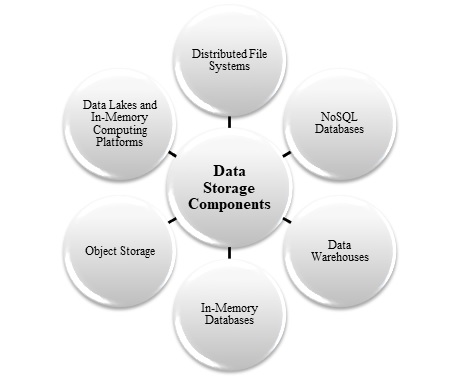
The selection of a data storage system is contingent on different aspects, including type of the data, performance requirements, scalability, and financial limitations. Different big data architectures use a blend of these storage systems to efficiently meet different use cases and objectives.
Batch Processing
Process data with long running batch jobs to filter, aggregate and prepare data for analysis, these jobs often involve reading and processing source files, and then writing the output to new files. Batch processing is an essential component of big data architecture, allowing for the efficient processing of large amounts of data using scheduled batches. It entails gathering, processing, and analysing data in batches at predetermined intervals rather than in real time.
Batch processing is especially useful for operations that do not require immediate responses, such as data analytics, reporting, and batch-based data conversions. You can run U-SQL jobs in Azure Data Lake Analytics, use Hive, Pig, or custom Map/Reduce jobs in an HDInsight Hadoop cluster, or use Java, Scala, or Python programs in an HDInsight Spark cluster.
Real-time Message Ingestion
Big data architecture plays a significant role in real-time message ingestion, as it necessitates the real-time capture and processing of data streams during their generation or reception. This functionality helps enterprises deal with high-speed data sources such as sensor feeds, log files, social media updates, clickstreams, and IoT devices, among others.
Real-time message ingestion systems are critical for extracting important insights, identifying anomalies, and responding immediately to occurrences. The following image shows the different methods work for real time message ingestion within big data architecture −
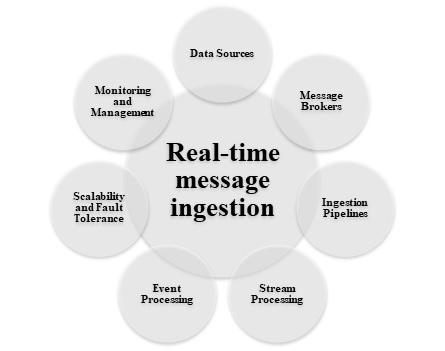
The architecture incorporates a method for capturing and storing real-time messages for stream processing; if the solution includes real-time sources. This could be a data storage system where incoming messages are dropped into a folder for processing. Nevertheless, a message ingestion store is necessary for different approaches to function as a buffer for messages and to facilitate scale-out processing, reliable delivery, and other message queuing semantics. Some efficient solutions are Azure Event Hubs, Azure IoT Hubs, and Kafka.
Stream Processing
Stream processing is a type of data processing that continuously processes data records as they generate or receive in real time. It enables enterprises to quickly analyze, transform, and respond to data streams, resulting in timely insights, alerts, and actions. Stream processing is a critical component of big data architecture, especially for dealing with high-volume data sources such as sensor data, logs, social media updates, financial transactions, and IoT device telemetry.
Following figure illustrate how stream processing works within big data architecture −
After gathering real-time messages, a proposes solution processes data by filter, aggregate, and preparing it for analysis. The processed stream data is subsequently stored in an output sink. Azure Stream Analytics offers a managed stream processing service based on continuously executing SQL queries on unbounded streams. on addition, we may employ open-source Apache streaming technologies such as Storm and Spark Streaming on an HDInsight cluster.
Analytical Data Store
In big data analytics, an Analytical Data Store (ADS) is a customized database or data storage system designed to deal with complicated analytical queries and massive amounts of data. An ADS is intended to facilitate ad hoc querying, data exploration, reporting, and advanced analytics tasks, making it an essential component of big data systems for business intelligence and analytics. The key features of Analytical Data Stores in big data analytics are summarized in following figure −
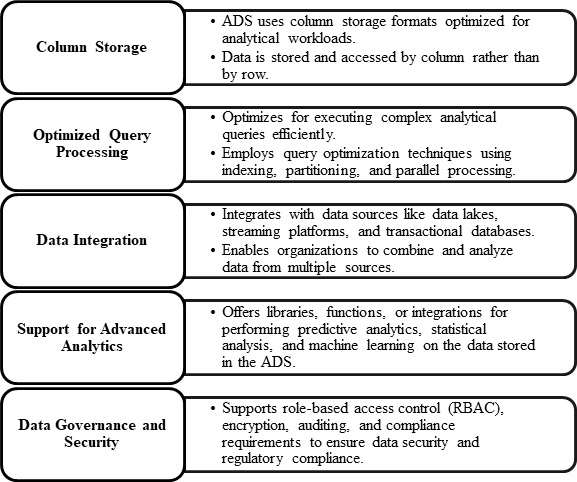
Analytical tools can query structured data. A low-latency NoSQL technology, such as HBase or an interactive Hive database, could present the data by abstracting information from data files in the distributed data storage system. Azure Synapse Analytics is a managed solution for large-scale, cloud-based data warehousing. You can serve and analyze data using Hive, HBase, and Spark SQL with HDInsight.
Analysis and Reporting
Big data analysis and reporting are the processes of extracting insights, patterns, and trends from huge and complex information to aid in decision-making, strategic planning, and operational improvements. It includes different strategies, tools, and methodologies for analyzing data and presenting results in a useful and practical fashion.
Following image gives a brief idea about different analysis and reporting methods in big data analytics −

Most big data solutions aim to extract insights from the data through analysis and reporting. In order to enable users to analyze data, the architecture may incorporate a data modeling layer, such as a multidimensional OLAP cube or tabular data model in Azure Analysis Services. It may also offer self-service business intelligence by leveraging the modeling and visualization features found in Microsoft Power BI or Excel. Data scientists or analysts might conduct interactive data exploration as part of their analysis and reporting processes.
Orchestration
In big data analytics, orchestration refers to the coordination and administration of different tasks, processes, and resources used to execute data. To ensure that big data analytics workflows run efficiently and reliably, it is necessary to automate the flow of data and processing processes, schedule jobs, manage dependencies, and monitor task performance.
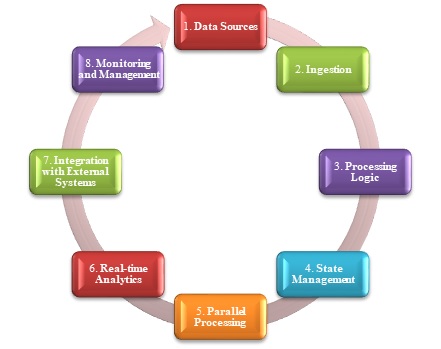
Following figure includes different steps used in orchestration −
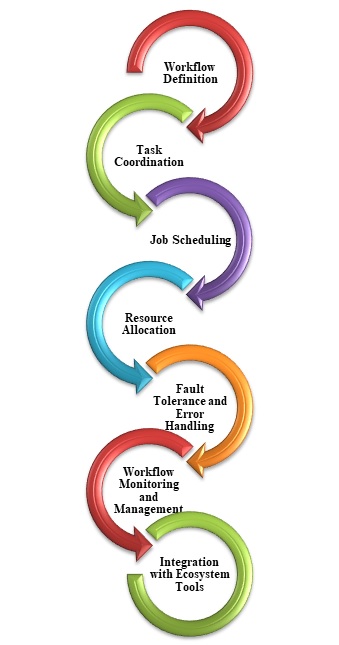
Workflows that convert source data, transport data across different sources and sinks, load the processed data into an analytical data store, or output the results directly to a report or dashboard comprise most big data solutions. To automate these activities, utilize an orchestration tool like Azure Data Factory, Apache Oozie, or Sqoop.